Building a Scalable WebRTC Architecture for Voice AI: A Step-by-Step Guide
Introduction
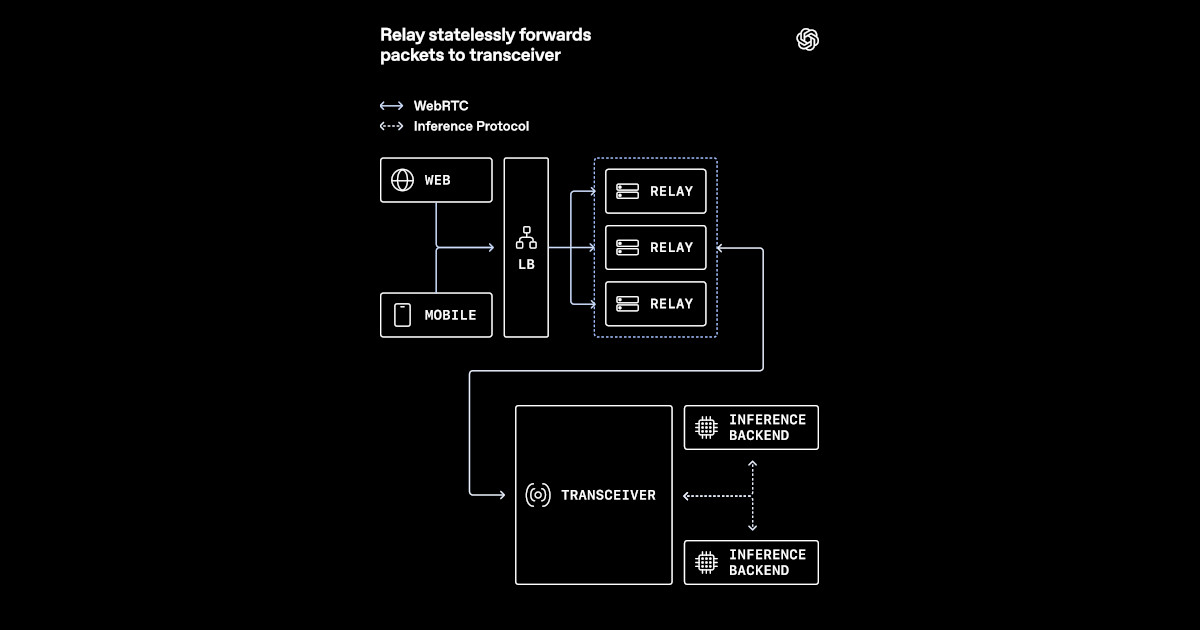
When OpenAI revealed its approach to scaling low-latency voice AI, it highlighted a shift from conventional media termination to a relay-transceiver design. This architecture not only handles the massive demands of real-time audio processing but also integrates smoothly with modern cloud infrastructure like Kubernetes and load balancers. If you're looking to deploy your own voice AI system that's both responsive and globally distributed, this guide walks you through the core principles that OpenAI employed. You'll learn how to restructure your WebRTC stack to minimize latency, reduce security risks, and keep media traffic flowing efficiently.
What You Need
- Familiarity with WebRTC basics – understanding of peer connections, ICE, and media streams.
- Container orchestration platform – Kubernetes (or similar) to manage microservices.
- Cloud load balancer – capable of handling UDP traffic (e.g., AWS NLB, GCP TCP/UDP LB).
- Relay servers – geographically distributed nodes (e.g., TURN servers) that can forward media.
- Transceiver layer logic – a service dedicated to maintaining WebRTC session state.
- Low-latency network – preferably with global edge points of presence.
Step-by-Step Implementation
Step 1: Replace Conventional Media Termination with a Relay-Transceiver Design
Traditional WebRTC architectures place the media termination (the endpoint that receives and sends audio/video) directly behind the load balancer. This forces every media packet to traverse through a central bottleneck, increasing latency and making scaling difficult. OpenAI instead adopted a relay-transceiver pattern. The idea is to separate the concerns: relays handle the raw media forwarding, while the transceiver manages session intelligence.
Action: Start by configuring your WebRTC infrastructure to have two distinct layers. Deploy a set of lightweight relay processes (often implemented as TURN or custom UDP forwarders) that only pass media packets without processing state. Then, behind these relays, deploy transceiver instances that interact with relays and handle signaling, codec negotiation, and session control. This separation allows each layer to scale independently.
Step 2: Keep WebRTC Session State in a Dedicated Transceiver Layer
In a conventional setup, session state (such as encryption keys, connection IDs, and codec preferences) is stored within the media termination process. When you scale horizontally, state becomes sticky to a specific pod, complicating load balancing. OpenAI solved this by moving all session state into a dedicated transceiver layer that is decoupled from media forwarding.
Action: Implement a stateful service (e.g., a Redis-backed, in-memory store) that records each WebRTC session's parameters. The transceiver instances query this state whenever a media packet arrives via a relay. Use consistent hashing or a distributed key-value store to ensure that any transceiver can retrieve the state for any session. This makes your infrastructure stateless at the relay level, allowing Kubernetes to scale relays without worrying about session affinity.
Step 3: Use Relays to Reduce Public UDP Exposure
Exposing your core services directly to the public internet over UDP is a security risk—attackers can flood your servers with media packets or exploit vulnerabilities in the WebRTC stack. By placing relays at the edge, you create a thin buffer that handles all incoming UDP traffic. Relays are designed to be minimal and secure, with no complex state, making them easier to harden.
/presentations/game-vr-flat-screens/en/smallimage/thumbnail-1775637585504.jpg)
Action: Configure your cloud load balancer to forward UDP traffic only to the relay nodes, not to the transceiver layer. Use a strict firewall policy that allows inbound UDP only from known relay IPs to the transceivers. Additionally, implement rate limiting on the relays per client to mitigate DDoS attacks. The relays can also perform basic validation (e.g., checking packet headers) before forwarding.
Step 4: Keep Media Routing Close to Users
Latency in voice AI is critical—every extra millisecond degrades the user experience. OpenAI ensured that media packets traverse the shortest possible path by deploying relays in geographically distributed locations close to end users. The relays then forward traffic to the nearest transceiver instance, which may be in a central region but via optimized network paths.
Action: Set up a global fleet of relay servers in major metropolitan areas or use an existing CDN's edge infrastructure. Use a geo-aware DNS or anycast to direct each user to the nearest relay. Inside your Kubernetes cluster, deploy transceiver pods across multiple cloud regions and use a service mesh or smart routing to forward traffic from relays to the closest transceiver. Continuously monitor RTT (round-trip time) and adjust relay placements.
Tips for Success
- Start with a proof of concept – Build a small test with one relay and one transceiver to validate the state separation before scaling globally.
- Monitor relay health – Since relays are stateless, you can scale them up/down aggressively. Use liveness probes and metrics (packet loss, latency, throughput) to auto-scale.
- Secure the transceiver layer – Place transceivers in a private subnet with strong authentication for relay-to-transceiver communication (e.g., mTLS).
- Test for session resumption – When a transceiver fails, ensure the new transceiver can pick up the session from the shared state store without interruption.
- Consider WebRTC optimizations – Use opus codec for low-bitrate voice, enable forward error correction, and adjust bitrate adaptively.
- Document your architecture – Create detailed diagrams of relay-transceiver interaction to help your team troubleshoot and iterate.
By following these steps, you can replicate the core pattern that OpenAI uses to deliver high-quality, low-latency voice AI at a global scale.
Related Articles
- Cloudflare's Strategic Pivot: Workforce Reduction Reflects AI-First Evolution
- 6 Ways PostgreSQL Is Powering the Future of Cloud and AI
- CSS & Web Platform Q&A: Clip-Path Puzzles, View Transitions, Scoping, and More
- Cloudflare Restructures for the AI Era: Workforce Reduction and Strategic Shift
- How to Optimize Prompts in Amazon Bedrock: A Step-by-Step Guide
- Browser Run Upgraded: Cloudflare Containers Deliver Speed and Scale
- How to Architect a Decision-Ready Data Ecosystem with Informatica and Salesforce
- Unlocking Enterprise AI: Key Q&A on SAP on Azure Innovations at SAP Sapphire 2026